GSoC Week 5: Lots of messages

Welcome to my second post, it’s going to be filled with lots of code as per usual and actual linking to repositories this time. This week I thought was going to be simple but boy was I wrong, ranging from combining all the mailing lists to just creating a new table, and let’s not even get started on adding the date column to the SQL table. I also had to go forward with formating the SQL table to a specific data types.
So this week’s task with my mentor Sean Goggins is as follows:
Goals for the week:
- Build the single, unified table for PiperMail Storage: Done, this is called “mail_lists”
-
Have your python program that imports from Perceval downloads to the database add backend_name (PiperMail), Project (which should be a parameter on a method that runs Perceval against a set of mailing lists.) This might include something like a “mailing list job table.” Right now, you have a table called “Mailing_Lists” with two columns. One is the backend, and the other is the link.
- Explore the pros and cons of different persistence strategies using two main use cases:
- Researchers trying to understand linguistic trends within and across lists
- Community managers and researchers identifying a set of email communications containing different linguistic properties. For example, sentiment analysis or some other linguistic marker.
- (Stretch Goal) : Experiment with ways of filtering out old message strings from mailing lists and identifying mailing list discussion threads (some lists have them automatically, some don’t)
Ongoing Tasks:
- The development / merge process
- Getting to the know the metrics
- Configuring Augur for different data backends (i.e. mailing lists)
Goals
Goal 1:
So for this goal we had to update the code from last, the problem with the code from last week was that it was separating each of the mailing lists into separate tables. After speaking with Sean we decided it would be best to have all the mailing list messages combines into one table to make it easier for someone to query something from the table. Now for me this was easier said than done, because for some of the messages they have a very long thread, now before I was ignoring the thread and only taking about 10000 characters in the message. If we look at line 2 we see that it’s just copying the contents of di[‘data’][‘body’][‘plain’] into temp which is the text in the message. Now in line 7 I just copy the first 10000 characters because when I tried to upload it to the SQL database I would get the error that data is being truncated because for example in one of the mailing threads there was around 240000 characters we can see it here.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def add_row_mess(columns1,df,di,archives):
temp = di['data']['body']['plain']
words = ""
for j in range(0,len(temp)):
words+=temp[j]
if(temp[j] == "\n" and j+1<len(temp)):
if(temp[j+1] == ">" or j>10000):
di['data']['body']['plain'] = words
break
li = [[di['backend_name'],di['origin'],archives,
di['category'], di['data']['Subject'],
di['data']['Date'], di['data']['From'],
di['data']['Message-ID'],
di['data']['body']['plain'] ]]
df1 = pd.DataFrame(li,columns=columns1)
df3 = df.append(df1)
return df3
So the solution that I came up with and well Sean was the one that guided me there was to just have multiple rows in the SQL Database to store the different parts of the message. Now a good chunk of my time was spent on this because well I’m using pandas and utilizing dataframes, so when I tried to copy the contents of the message up to a certain point, in this case I went up to 5000 characters (line 11) I would store it in a dataframe (line 24) and then append that dataframe to the original dataframe I passed to the function (line 1). Now I spent hours not realizing that that initial dataframe df needed to be passed back df3 so that the addition would be fully completed in the loop, what was happening is that I would just copy the last message in the long message.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def add_row_mess(columns1,df,di,row,archives):
temp = di['data']['body']['plain']
words = ""
k = 1
val = False
#print(temp,"\n\n\nHEREEEEEEEEEEEEE!!!!!!!!!!!\n\n\n")
prev = 0
if(len(temp) < 100):
j = len(temp)
else:
for j in range(100,len(temp),5000):
k+=1
#date[5] = date[5][0:1] + ':' + date[5][1:3]
#print(date[5])
split = di['data']['Date'].split()
s = " "
date = parse(s.join(split[:5]))
zone = split[5]
li = [[di['backend_name'],di['origin'],archives,
di['category'], di['data']['Subject'],
date, zone,di['data']['From'],
di['data']['Message-ID'],
temp[prev:j] ]]
df1 = pd.DataFrame(li,columns=columns1)
df3 = df.append(df1)
df = df3
prev = j
row+=1
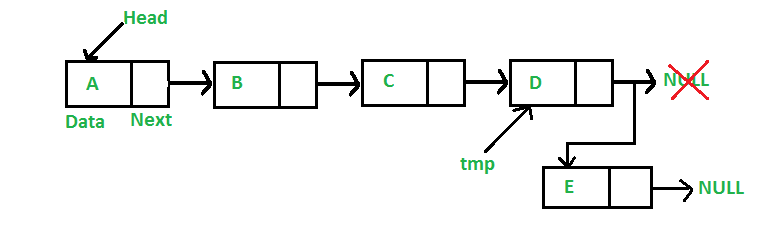
I thought about it in terms of a linked list and inserting at tail but I was just inserting it at the tail and moving tmp to that new tail, I was instead still at prev and just kept adding tail to tmp.
So before I even get started on my problem with the Date column in the SQL table I will just show you the outline for the Database:
1
2
3
4
5
6
7
8
9
10
11
12
df5.to_sql(name=db_name, con=self.db,if_exists='replace',index=False,
dtype={'backend_name': s.types.VARCHAR(length=300),
'project': s.types.VARCHAR(length=300),
'mailing_list': s.types.VARCHAR(length=1000),
'category': s.types.VARCHAR(length=300),
'subject': s.types.VARCHAR(length=400),
'date': s.types.DateTime(),
'timezone': s.types.VARCHAR(length=5),
'message_from': s.types.VARCHAR(length=500),
'message_id': s.types.VARCHAR(length=500),
'message_text': s.types.Text
})
That’s the code for it and it comes out for the column names in the table as seen below
1
| backend_name | project | mailing_list | category | subject | date | timezone_UTC | message_from | message_id | message_text |
Now we’re going to refer back to this piece of code I showed you before and specifically lines 16-19.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from dateutil.parser import parse
def add_row_mess(columns1,df,di,row,archives):
temp = di['data']['body']['plain']
words = ""
k = 1
val = False
#print(temp,"\n\n\nHEREEEEEEEEEEEEE!!!!!!!!!!!\n\n\n")
prev = 0
if(len(temp) < 100):
j = len(temp)
else:
for j in range(100,len(temp),5000):
k+=1
#date[5] = date[5][0:1] + ':' + date[5][1:3]
#print(date[5])
split = di['data']['Date'].split()
s = " "
date = parse(s.join(split[:5]))
zone = split[5]
li = [[di['backend_name'],di['origin'],archives,
di['category'], di['data']['Subject'],
date, zone,di['data']['From'],
di['data']['Message-ID'],
temp[prev:j] ]]
df1 = pd.DataFrame(li,columns=columns1)
df3 = df.append(df1)
df = df3
prev = j
row+=1
Now my problem when using a function called parse (line 1) is that in the json file the format looks like this
"Date": "Fri, 23 Oct 2015 14:07:16 +0000",but when I used the parse function it was formatting it as a datetime64 object in pandas and when trying to append this to another dataframe it was not having it. After working on it for about three hours getting the same error continuously “date type not understood” I decided let’s see how it looks in the database as just a string and when uploading it, it actually cut off the timezone. So I was like you know what I’m just going to upload the timezone separately and everything worked fine from there the datetime object was okay and the timezone had it’s own column. So yes before timezone wasn’t initially a column heading.
Goal 2:
So for this goal I think I might need to clarify if what I have in the jupyter notebook is fine or if I need to change some things.
Goal 3:
I don’t think you all realize how pumped I am for this part of my work, because this will actually involve using things related to NLP(Natural Language Processing). I am really excited to start this, but we haven’t reached there as yet.
Goal 4:
And for this part we haven’t discussed it as much but what I’m seeing from the threads I’ve looked at in the mailing lists they seem to use ‘>’ to indicate a thread but this is used for other things, so some more thought is going to have to be put into this.
Ongoing Tasks
Well I could give just a general answer to these, it’s ongoing so you know pushing things to the Augur git repository (I’m on the pipermail branch of the project). And well I’m hopefully finishing the pulling of mailing lists.
Links: Office gif
Files Used:
Python File - PiperRead 7
Jupyter Notebook - PiperMail