GSoC Week 9: Oh you like drawing?
To answer that the title no, I definitely don’t like drawing but if a computer does it for me then it’s fine (I still have some reservations even then). My sixth blog post, okay so it seems to be a thing that’ actually happening now, well that’s good to hear. So this week we actually have some visualisation this time, but mostly I was fixing something that I didn’t even realize was wrong until new messages for a mailing list for this month popped up.
So this week’s task with my mentor Sean Goggins is as follows:
Goals for the week:
- Update the sentiment scores per message and store them in the database using NLTK.
- Using Python or Augur, build a visualization of how the sentiment of messages evolves over time on a project mailing list or set of mailing lists.
- Begin working with the “Toxicity Detection Team”
#Back from the Grave 4) Include logic to keep track of the timestamp of the LAST message retrieved on each “load” …. add a “last_run” column to mailing_list_jobs, and then download only the mboxes not already included, and, for the oldest one, you will likely need to look for messages > the “last_run” column timestamp. All the UTC conversions need to occur before this comparison …
Goals
Goal 1:
So this was actually implemented last week and all I did was just check that it was correct, to my knowledge it is but you know overtime I’ll check it just to make sure.
Goal 2:
Now this actually required writing some code but to be honest it wasn’t that tough, I think I spent more time getting the scores so after other things like creating visualizations really just meant taking the data that I had and just outputting it in different ways. So I created a simple line chart using matplotlib, as seen below I just use a for loop (lines 5-20) to group together the dates and the scores (lines 6 and 7)and use that to plot those values (line 13). It’s strange because for the first image it does it by months but for the second image it’s by days, I’m assuming that if it has too many days in the month it just groups the month together.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
grouped = combine.groupby('mailing_list').groups
dates = []
values = []
mail_list = None
for group in grouped:
dates = (combine.loc[combine['mailing_list'] == group]['date']).tolist()
values = (combine.loc[combine['mailing_list'] == group]['score']).unique().tolist()
x = np.array(dates)
dates = np.unique(x)
#print(dates)
dates1 = [x.to_pydatetime() for x in dates]
dates2 = mdates.date2num(dates1)
plot.plot_date(dates2, values)
plot.plot(dates2,values)
# beautify the x-labels
plot.gcf().autofmt_xdate()
plot.title("Mailing list: " + group)
plot.ylabel('Score')
plot.xlabel('Date')
plot.show()
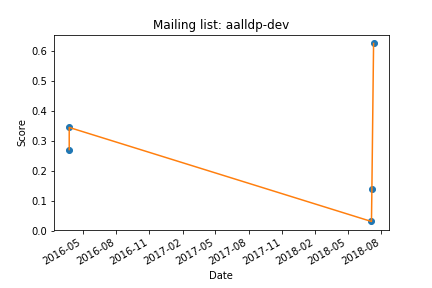
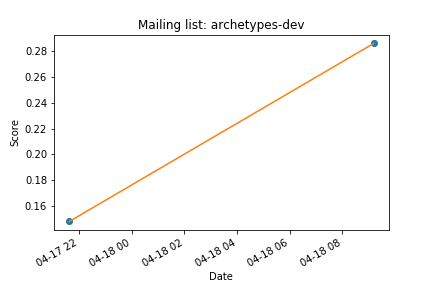
Goal 3:
Now for this I had to attend a meeting and what it is at least to my knowledge so far is to help pull examples of very toxic email and github issues to be used to detect toxicity in a community and when were the triggering events. I was given some examples as to some toxic events in some communities however the mailing archives I was looking at was hosted using something called Hypermail which is a problem because it this turns the emails which are in MBOX format to an html format. So it seems that I can’t use Pipermail from Perceval so I need to get that sorted out when I speak with Sean again. However I was able to pull github issues as seen below. I just need to clarify what I have to do next with these issues I know I have to put a score but do I have to create a new SQL table to store? Should get these answers soon enough. This code is in the jupyter notebook Issues_pull
from perceval.backends.core.github import GitHub
from datetime import date
import datetime
import dateutil.tz
from dateutil.relativedelta import relativedelta
import matplotlib.pyplot as plt
# Url for the git repo to analyze
#repo_url = 'https://github.com/chaoss/grimoirelab-perceval'
repo_url = 'CTC'
# Directory for letting Perceval clone the git repo
#repo_dir = 'CTC'
token = 'Insert_github_token_here'#I have my own token
own = 'nodejs'
# ElasticSearch instance (url)
#repo = 'grimoirelab-perceval'
# Create the 'commits' index in ElasticSearch
# Create a Git object, pointing to repo_url, using repo_dir for cloning
repo = GitHub(owner=own,repository=repo_url,api_token=token)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
date = datetime.datetime(2017, 8, 7, 0, 0, 0,
tzinfo=dateutil.tz.tzutc())
i=0
for issues in repo.fetch(from_date=date):
# Create the object (dictionary) to upload to ElasticSearch
# Create the object (dictionary) to upload to ElasticSearch
#if(i==90):
if 'pull_request' in issues['data']:
continue
else:
if(issues['data']['state'] == 'closed' and "165" in \
issues['data']['comments_url'] ):
print(issues['data']['body'])
print("\n\n\n")
print(issues['data']['comments_data'][0]['body'][:1000])
#print(issues['data'][''])
i+=1
I'm not going to go into a rehash of all the details here. Our process guidelines require that in order to request that an individual be removed from the CTC an issue needs to be opened and put on the CTC agenda. So I'm officially asking that either Rod resign from the CTC voluntarily or a decision be made by the CTC to remove him on grounds that interactions with the community and with other members of the CTC and collaborator base have not been becoming of a CTC member.
I do not believe that this decision needs to be deferred until after the proposed CTC/TSC merger but doing so would likely be best.
Note: I am locking this thread to prevent outside trolling. I am also not going to respond further on this thread.
_Dear reader from `${externalSource}`: I neither like nor support personal abuse or attacks. If you are showing up here getting angry at any party involved, I would ask you to refrain from targeting them, privately or in public. Specifically to people who think they may be supporting me by engaging in abusive behaviour: I do not appreciate, want or need it, in any form and it is not helpful in any way._
Yep, this is a long post, but no apologies for the length this time. Buckle up.
I'm sad that we have reached this point, and that the CTC is being asked to make such a difficult decision. One of the reasons that we initially split the TSC into two groups was to insulate the technical _doers_ on the CTC from the overhead of administrative and political tedium. I know many of you never imagined you'd have to deal with something like this when you agreed to join and that this is a very uncomfortable experience for you.
It's obvious that we never figured out a suitable structure th
Goal 4:
We head back and look at what did I actually did not implement correctly with the most recent message download for the mailing archive. Now before I was ensuring that the emails that were being downloaded were more recent than when I first downloaded the emails I would store the most recent message. When I downloaded new messages I would store the most recent message date but I actually didn’t do anything with it. So now this week I actually went about updating the SQL table ‘mailing_list_jobs’ with the most recent date. A problem I had was when I pulled ‘mailing_list_jobs’ and tried to update a row, I was required to have a primary key, now before this I had no use for a primary key so I had to set one so I created a new column ‘augurlistID’ (line 15) and set that as the primary key (line 24). This is in PiperMail
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
table_names = s.inspect(connect.db).get_table_names()
print(table_names)
val = False
mail_lists = True
if("mail_lists" not in table_names):
mail_lists = False
if("mailing_list_jobs" in table_names):
lists_createdSQL = s.sql.text("""SELECT project FROM mailing_list_jobs""")
df1 = pd.read_sql(lists_createdSQL, connect.db)
print(df1)
val = True
else:
columns2 = "augurlistID","backend_name","mailing_list_url","project","last_message_date"
df_mail_list = pd.DataFrame(columns=columns2)
df_mail_list.to_sql(name="mailing_list_jobs",con=connect.db,if_exists='replace',index=False,
dtype={'augurlistID': s.types.Integer(),
'backend_name': s.types.VARCHAR(length=300),
'mailing_list_url': s.types.VARCHAR(length=300),
'project': s.types.VARCHAR(length=300),
'last_message_date': s.types.DateTime()
})
lists_createdSQL = s.sql.text("""SELECT project FROM mailing_list_jobs""")
df1 = pd.read_sql(lists_createdSQL, connect.db)
connect.db.execute("ALTER TABLE mailing_list_jobs ADD PRIMARY KEY (augurlistID)")
print("Created Table")
The next step was to go back to PiperRead and set it so that if the date of the newly downloaded messages is more recent than the one stored in ‘mailing_list_jobs’ then the most recent message date is updated to ‘last_date’ in the SQL table.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
if(last_date < temp_date):
last_date = temp_date
print(last_date)
if(mail_check[archives[i]] == 'update'):
print(res)
print("sigh")
y=0
print(res[y].project)
while(res[y].project!=archives[i]):
y+=1
print(res[y].project)
res[y].last_message_date = last_date
session.commit()
Resources:
GSoC ideas (Specifically Ideas 2 & 3): Ideas
My proposal: My proposal
Files Used:
Python File - PiperRead 14
Jupyter Notebook - PiperMail 9
Jupyter Notebook - Sentiment_Piper 7
Jupyter Notebook - Issues_pull