GSoC Week 11: Let's take a moment
Okay so we’re coming down to the finish line just about less than 3 weeks remaining, so let’s see if we can get through pulling more data and doing some more analysis. Although my plan is to still work on this outside of GSoC (Google Summer of Code) it’s definitely an opportunity to contribute outside of school and I get to practice my programming skills outside of school. Also I’m going to try and integrate a better way of documenting my code because to conform to PEP (Python Enhancement Proposal). I’m pretty sure that one may take awhile though because it’s pretty new to me.
So this week’s task with my mentor Sean Goggins is as follows:
Goals for the week:
- Examine the following GitHub repo issues and pull request comments using the software engineering sentiment analysis strategy that Kelly Blincoe provided:
- https://github.com/nodejs/CTC/
- https://github.com/nodejs/TSC/
- https://github.com/torvalds/linux
- Investigate non-Perceval mechanisms for getting HTML stored email lists.
Goals
Goal 1:
Now starting with the first goal we actually split it up into two tasks, the first one being pulling the github repo issues and the next being pulling the github pull requests. We will go about looking at pulling the github issues which we have been doing over the past few weeks.
Github Issues
The only improvement I made really was reading the data about a user from the augur.config.json file, and we just go about download the different issues from the github repositories.
1
2
3
4
5
6
7
8
9
10
if("notebooks" not in os.getcwd()):
os.chdir("notebooks")
augurApp = augur.Application('../augur.config.json')
connect,list1,path = augurApp.github_issues()
token = list1[5]
DB_STR = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(
list1[0], list1[1], list1[2],\
list1[3], list1[4]
)
db = s.create_engine(DB_STR)
After we look at creating visualizations for the different repositories in terms of the sentiment analysis. However I did add so that we check to see if you have the necessary packages to use sentiment analysis in python. I will need to do some testing on this most likely in a virtual environment.
1
2
3
4
5
6
7
8
9
# Install a pip package in the current Jupyter kernel
import sys
!{sys.executable} -m pip install nltk
import nltk
nltk.download('vader_lexicon')
nltk.download('punkt')
nltk.download('stopwords')
!{sys.executable} -m pip install scipy
from scipy import stats
After running most of the code we have before we can actually see some interesting graphs. Also the only reason we aren’t seeing a graph for ‘https://github.com/torvalds/linux’ is because that repository doesn’t have an issues section but only has pull requests and we will get into an issue with that repository later on.
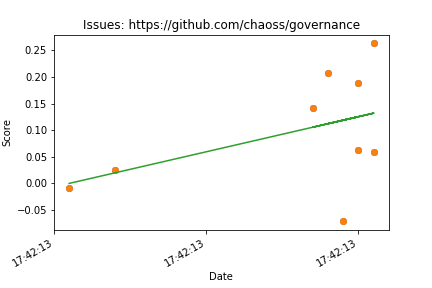
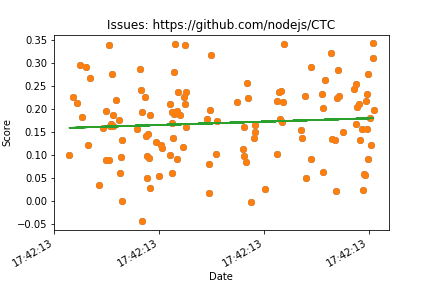
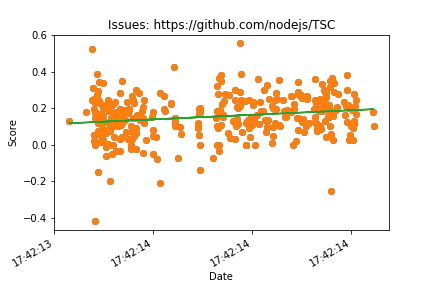
Pull requests
Next we look at pull requests, the nice thing about this is that it’s more or less the same as the jupyter notebook ‘github_issues’ the only change is some of the column names
df.to_sql(name="github_pull_requests", con=db,\
if_exists='replace',index=False,
dtype={'augurmsgID': s.types.Integer,#0
'backend_name': s.types.VARCHAR(length=300),#1
'repo_link': s.types.VARCHAR(length=300),#2
'owner': s.types.VARCHAR(length=300),#3
'repo': s.types.VARCHAR(length=300),#4
'subject': s.types.VARCHAR(length=300),#5
'status': s.types.VARCHAR(length=10),#6
'category': s.types.VARCHAR(length=10),#7
'pull_request_number': s.types.Integer,#8
'timestamp': s.types.Integer,#9
'pull_request_id': s.types.Integer,#10
'user': s.types.VARCHAR(length=100),#11
'body':s.types.TEXT#12
})Now we actually encounter an issue here because due to the amount of issues in ‘https://github.com/torvalds/linux’ and I need to look at the length of how many comments are in this issue also but it seems that it exceeds the limit of how many issues can be downloaded using the github API token. So I actually encounter a problem where my rate is reset but normally I have to wait about 40 minutes each time. I need some time to go about testing what I need to change in terms of making perceval sleep for a time.
Goal 2:
Now I need to do some research about how I can go about improving this because as you know from last week we encountered the problem where for example for the LKML (Linux Kernel Mailing List) the archives for their emails aren’t easily accessible to iteratively download them. So we are going to look at how we can download messages from emails stored on a mailing list that is in HTML format.
Resources:
GSoC ideas (Specifically Ideas 2 & 3): Ideas
My proposal: My proposal
Files Used:
Python File - PiperReader 16
Jupyter Notebook - PiperMail 11
Jupyter Notebook - Sentiment_Piper 8
Jupyter Notebook - github-issues 3
Jupyter Notebook - github_issues_scores 5
Jupyter Notebook - github_pull_requests
Jupyter Notebook - github_pull_requests_scores